jan.bio
Beetles in the wild: A Semantic Mashup based on Topic Maps
My plan was to finish this blog post long before the Topic Maps 2010 conference in Oslo, but unfortunately, I didn’t make it. Inspired by the discussions about semantic mashups on the Topic Maps mailing list a while ago, I started thinking about how I could combine Topic Maps with other web services. This blog post is about what I came up with. In one of my last posts I presented how parts of the Norwegien Red List of Threatended species can be transformed into a topic map. Now, I’ll show you how this topic map can be used to annotate web sites with the subjects stored in this map.
The basic idea of my mashup is to send textual data that is part of a
web site to a service on the server hosting the topic map. The server
posts the text to the taxonFinder web service at ubio.org which
extracts biological names and returns an XML structure will all
recognized names contained in the text. These names are then matched
agains the species in the Red List topic map. The result which is sent
back to client consists of all red-listed species including their Red
List status together with their Published Subject Identifier. This is
a rough overview of the mashup:
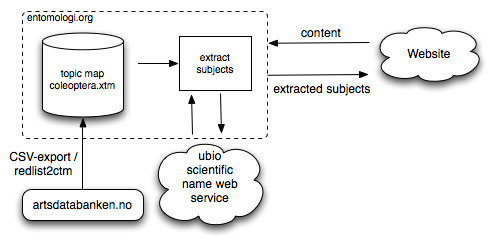
The plan is to annotate a text in a web side with information from the Red List. Assume that this is our original HTML contained in a web page:
<p id=”content”>Agonum muelleri is a 7-9.5mm long black beetle, with
brassy or purplish elytra and bright green reflecting, metallic
foreparts. It occurs on open, moderately dry ground, including arable
land. Widely distributed. Agonum marginatum is a 8.5-10.5mm long
bright metallic green beetle with conspicuous yellow sides to the
elytra. Locally common in marshy places, especially bare mud at the
side of ponds and lakes.</p>
(original text taken from Ground Beetles of Ireland).
With over 800 beetle species on the Red List it is hard to remember the status of all beetles, and instead of looking up every species name in the printed version, I want to do this automatically in the web browser. The text mentions Agonum marginatum, a species which unfortunately is listed as endangered on the Norwegian Red List. I want to annotate species names like this:
<p id=”content”>Agonum muelleri is a 7-9.5mm long black beetle, with
brassy or purplish elytra and bright green reflecting, metallic
foreparts. It occurs on open, moderately dry ground, including arable
land. Widely distributed. <span class=”Redlist2006EN”
rel=”http://psi.entomologi.org/coleoptera/agonum_marginatum”>Agonum
marginatum</span> is a 8.5-10.5mm long bright metallic green beetle
with conspicuous yellow sides to the elytra. Locally common in marshy
places, especially bare mud at the side of ponds and lakes.</p>
Note that the uBio service recognizes Agonum muelleri and Agonum marginatum as biological names, but only Agonum marginatum is on the Red List. You can take a look at the final result.
Implementation details
In this section I’ll present a few implementation details of both the client and the server. In its current state, all that is needed to enable the service in a client page is to include of a little JavaScript file named coleoptera.js to get access to the name extraction service and some logic to annotate the HTML code. For simplicity, I’ve included jQuery via the Google AJAX Libraries API. Here is the head section of the web page that we are going to annotate:
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<title>A Semantic Mashup with Topic Maps (Demo)</title>
<script src="http://www.google.com/jsapi?key=XXXXXXXXXXXXXX" type="text/javascript"></script>
<script type="text/javascript" src="coleoptera.js"></script>
<link rel="stylesheet" type="text/css" media="all" href="coleoptera.css" />
<script type="text/javascript">
//<![CDATA[
google.load("jquery", "1.4.2");
google.setOnLoadCallback(function () {
var id = 'content';
Coleoptera.extract_subjects($('#'+id).get(0),
function (subjects) {
var i, sp;
if (subjects && subjects.status === 'success') {
for (i=0; i<subjects.result.length; i+=1) {
sp = subjects.result[i];
$("#"+id).html($("#"+id).html().replace(new RegExp(sp.name),
'<span class="species redlist-'+sp.redlist+'" title="'+sp.psi+'">'+sp.name+'</span>'));
}
}
});
});
//]]>
</script>
As you can see, all the client has to do to extract red-listed species names is to call the Coleoptera.extract_subjects(node, callback) with a DOM node containing the unannotated text and a callback function which is later called with the extracted subjects as a parameter. The result of the web service is basically a JSON-encoded array of species names together with their PSI and their Red List status. In a real-world scenario it would be interesting to implement this service as a browser plug-in, which would enable you to annotate any web site. But, for simplicity, I’ve chosen to integrate the code directly into the page. Now, that you’ve seen what the page on the client looks like, let’s take a look at coleoptera.js:
The first step is to extract the text from a DOM node. The node itself might contain more HTML elements, but we are only interested in the text:
extract_text = function (node) {
var i, text, child_txt, skipnodes = ['SCRIPT', 'OBJECT', 'EMBED', 'STYLE']; // more...?
// Check if the node should be skipped
if (node.nodeType === 1) {
for (i=0; i<skipnodes.length; i+=1) {
if (node.nodeName === skipnodes[i]) {
return '';
}
}
}
if (node.nodeType === 3 && node.nodeValue.match(/\S/)) {
return node.nodeValue;
} else {
text = '';
for(i=0;i<node.childNodes.length;i+=1) {
child_txt = extract_text(node.childNodes[i]);
child_txt = trim(child_txt);
if (child_txt !== '') {
text += ' '+child_txt;
}
}
return text;
}
};
The trim() function is trivial and not shown here. extract_text()
starts with a DOM node and walks through all node elements that are
not script, object, embed or style and collects the contained text
nodes. Now, that the script has extracted the text, it needs to be
send to the server, and this is where the real work happenens. The
function that sends the code to the server is quite simple:
extract_subjects = function (node, callback) {
var text = extract_text(node);
$.ajax({
url: 'http://www.entomologi.org/coleoptera/mashup/text2subj.php',
type: 'POST',
data: {q: text},
dataType: 'json',
timeout: 10000,
success: function(json){
json.status = 'success';
callback(json);
}
});
};
Now to the server-side part of the application. As mentioned earlier,
the mashup uses the uBio taxonFinder service. Calls to the service are
a simple HTTP GET request to this URL, with FOOBAR being the
url-encoded text to be analyzed:
http://www.ubio.org/webservices/service.php?function=taxonFinder&includeLinks=0&freeText=FOOBAR
Putting the text into the URL has the drawback that the length of the
URL which the uBio web server can handle is limited. POST might have
been a better choice for uBio, but there is also the possiblity to
send an URL to the document to extract from. The reason why I didn’t
supply a URL was that I wanted to be able to analyse only parts of a
web page. In a real world scenario the script would have to split the
text into chunks and analyze each of them. uBio keeps a database of
over 11,000,000 scientific names from various sources, so chances are
high that names will be recognized. It should be easy to dump all
names from the Red List into a text file and check how many of the
names are missed by the taxonFinder service.
taxonFinder returns an XML string with all recognized names. The script parses the XML with PHP’s SimpleXML API. The names are then transformed into PSIs, which is possible because I used a simple pattern to convert scientific names into PSIs. Basically, the name is converted to lower case and all characters that are not in the range a-z are converted to _, with no double underscores. The resulting string is prefixed with http://psi.entomologi.org/species/coleoptera/. The PSIs are then looked up in my Red List topic map. If the topic exists, the occurrence of type Red List status is fetched and the resulting list is converted into JSON and sent back to the client. Note that the PSI trick works fine in this case because the scientific names are unique within the order Coleoptera which is at least true for the Scandivian fauna.
Limitations
The presented prototype has some limitiations. Some can be solved easily, some not. First, the uBio web service has a relativly short limit for the text to analyse. In a real world scenario we would have to split the text in smaller chunks which are processed one by one. A second short coming is that the uBio has not registered all known Scandinavian species, so some names will not be recognized at all. Another problem are synonyms. Since the taxonFinder service will not resolve synonyms for all species, I would have to add PSIs that encode common synonyms to my Red List topic map. Alternatively, I could try to find topics by their names instead of PSIs, but this again would require me to add all or as many synonums as possible my toipc map. However, synonym databases exist on the web, so it is possible to write a script that fetches known synonyms and adds them to my map.
Outlook
As you have seen, this prototype has many limitations. I wish I chould have used standardized protocol to extract subjects from a text. Maybe a variant of Lars Marius’ get-topic-page that could take a text as a parameter and returns a topic map fragment would be a solution. Another shortcoming is that the page itself has to include coleoptera.js. It would be interesting to create a browser plugin that allowed me to mark a text within a web page and extract the contained subjects. taxonFinder is also able to extract specimen names from other documument formats, e.g. PDFs, so a browser plug-in could handle those document types as well.
I hope that I could show you how easy it is to combine Topic Maps with other web services and apply the result to a web page. Try it if you havn’t done so already. I’m interested in all kinds of feedback as well, so feel free to leave a comment!
